Will Predictive Analytics in Insurance Give Carriers a Competitive Edge?
Data-driven organizations in the U.S. have a 23 times higher probability of using data to acquire customers than those that don’t. Insurance carriers have no dearth of data and what can set them apart is their capacity to mine their data for better insights. Here is the reality though, a study conducted by The Economist Intelligence Unit (EIU) of 200 banking and insurance C-suite leaders found that while there is strong confidence in the benefits that AI can bring, only 15% said that AI is used extensively throughout their organization. This gap though is bound to be soon filled, with 89% of North American respondents saying they plan to invest over the next five years in incorporating insurance data analytics for better predictions of their big data.
Here are some more interesting insights for AI-fueled growth opportunities in the next 5 years:
-
27% of C-suite executives say AI will open up new products and services
-
25% expect it to lead the way in opening up new markets
-
25% expect AI to play a leading role in innovation
-
29% expect that in 5 years they will move to 51-75% of the workload being supported by AI technology
The good thing about insurance carriers is that they truly understand money as an asset. By that basis, Big Data and technologies like AI, Machine Learning, and Predictive Analytics are also assets that can improve ROI by significant numbers. That’s why business leaders are now, more than ever, willing to make the initial investment needed.
Machine Learning vs Predictive Analytics - the data science in insurance
Organizations are overflowing with data but yet are struggling to make sense of it. Insurance carriers are using only 15% of their structured data, stored in traditional databases. The opportunity is immense to bring in Machine Learning and Predictive Analytics to mine insights not only from structured data but also unstructured data like social media, audio, and video content.
Machine Learning and Predictive Analytics are not the same, the two approach a problem in different ways.
Machine learning is the poster child of Artificial Intelligence because it is a technology that gets smarter the more it is used. Machine Learning can be used on its own and functions on algorithms that are fed data and allowed to process it without any predetermined rules. ML models make their own assumptions, test them and learn on their own without being programmed.
Claims processing is the best insurance use case that showcases Machine Learning. ML has improved the process by triaging claims through an app or a virtual assistant. It can track and identify patterns in claims to identify any instances of outliers and even identify fraud. Once a potential fraud is detected, it uses internal dashboards to alert brokers to investigate. It cannot, though, predict future outcomes.
For predictive analytics, ML is just another tool in its toolbox that also contains data mining and predictive modeling. It uses both historical and current data to estimate future outcomes. For example, what behaviors customers might be likely to exhibit in different situations or even possible changes in the market.

Also read: Are Insurers Leveraging Bots to Boost Workforce Productivity?
The present and future of predictive analytics in the U.S. insurance industry
The industry is already on course for a tech-driven shift, moving from a “detect and repair” to a “predict and prevent” model because of a new wave of deep learning techniques. Everyone stands to gain by using data effectively. The next five years will see the adoption of predictive analytics in insurance in the following three core areas
-
Pricing and risk management using predictive analytics
Traditional pricing uses minimal pricing bands and consumers are allocated to each band based on a few variables such as the value of what is being insured or in other instances, age, income, and claims history.
Auto insurance is already beginning to leverage telematics to drive usage-based insurance and that will be one component of predictive underwriting. While predictive underwriting will take many new variables for a more accurate risk assessment, these results must be clearly explainable to the consumer to justify premium rates. If a driver can get a lower premium irrespective of age if the predictive model rates them as a “safe driver”, then customer retention is already a given because this level of personalization will keep a customer happy. Conversely, a higher premium might be just the push for a consumer to assess the impact of their driving skills on insurance premiums. This is a much more reliable way of pricing than the statistical model that charges a higher premium to a 20-year-old man compared to a woman of the same age.
The use of AI and predictive analytics will speed up underwriting and due diligence by combing through data from multiple sources. Data analytics in the insurance sector will not only use connected devices but also identify the current trends and risks; and also assess individual risk through behavior signals and underwrite accordingly, all in the shortest time possible. Comprehensive data analytics will enable more insurers to shift to pay-as-you-go and dynamic pricing models.
-
Identifying customers at risk of cancellation
Acquiring a new customer can be five times costlier than retaining one. If customer retention can be increased by just 5%, it could push up profits by a minimum of 25%. Another clinching reason for the adoption of predictive analytics in insurance is this - the success rate of upgrading an existing customer is 60-70% while selling to a new customer has a success rate of only 5-20%.
Insurance carriers in America are losing millions of dollars because of churned customers. Insurance predictive modeling has already shown initial success in improving customer retention.
Each customer’s journey is unique and there are multiple factors that can lead to policy cancellations. This is why a unidimensional model cannot be effective. The objective of insurance predictive modeling should be to go beyond identifying customers “at-risk” or “not at risk”. It should look at subtle nuances, like why would a customer cancel, at which stage could they decide to cancel how valuable these customers are, and what offers would help retain them,
The right approach is to have multiple predictive models, each one predicting one dimension of customer behavior that precedes a cancellation.
The right approach is to have multiple predictive models, each one predicting one dimension of customer behavior that precedes a cancellation. Attributes like gender, age, occupation, income, policy selected, credit score, and other variables are already a part of data science in the insurance industry.
What is important is knowing which attributes are at higher risk for customers moving away. For instance, perhaps a combination of attributes like higher premium and lower-income might have higher retention rates. Often, less obvious causes are even more likely for customer churn such as changes in income or change in a life circumstance and this needs external data to be added to the predictive modeling in insurance. Other causes might need tracking of unstructured data in internal processes such as an unhappy customer support experience or frustration with the claims process.
Predictive models need to be built on multiple use cases. While one predictive model can identify at-risk customers, another model needs to identify opportunities to retain the customer.
Also read: What it Takes to Reduce Technical Debt in Insurance Systems
-
Improving success rate in fraud detection
P&C insurance carriers estimate a 10% business loss due to fraudulent claims. Criminals are constantly evolving their techniques through complex schemes such as staged accidents, disaster relief falsification or even premium diversion by agents. The Coalition of Insurance Fraud says that $80 billion is lost through fraudulent claims in the United States, each year. Insurance companies are usually reactive to dealing with fraudulent activity but criminals are constantly finding new schemes that pay off.
If predictive analytics in insurance can proactively help in detection then this would be an incentive for insurers to invest in the technology.
Insurance predictive modeling for proactive fraud detection can identify patterns and anomalies in big data to highlight the characteristics of a fraudster. The technology uses advanced analytical tools like logistics regression and Gradient Boosting Model (an ML technique) to identify the possibility of a scam at First Notice of Loss (FNOL), rather than wait for weeks for a full review. It can also be used during the underwriting process before even a policy is sold.
Predictive analysis is the best way to map possibilities to make better business decisions. To leverage data analytics in the insurance sector, it needs a tech stack, like SimpleINSPIRE, that can integrate with insurance predictive modeling layers.
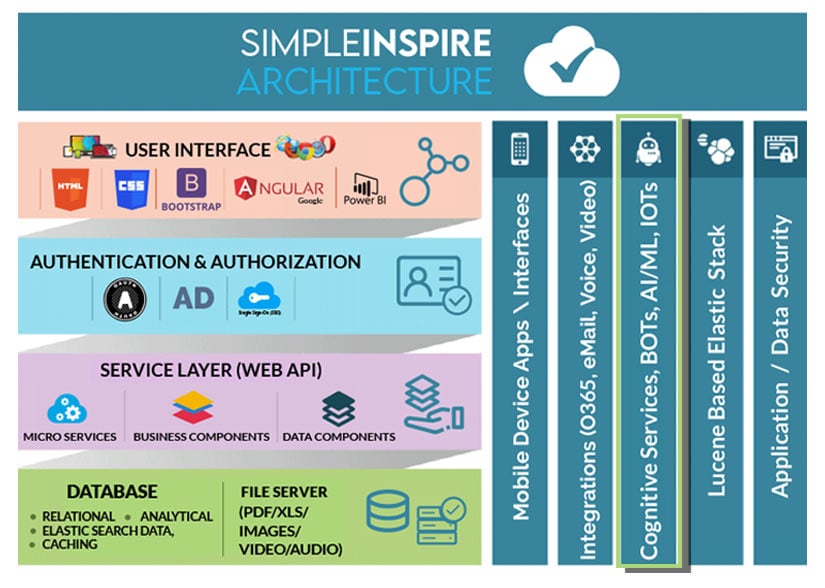
SimpleINSPIRE from SImpleSolve makes it easier to introduce modern technologies through a web-based Insurance Application Suite that is both feature-rich and can easily integrate with new-age disruptive technologies such as Machine Learning and IoT. The system is highly scalable, which means the system will enable +B23 growth and never limit it. Speak to our experts to find out more.
Topics: AI in Insurance
Source URL: - https://www.simplesolve.com/blog/predictive-analytics-in-insurance

Comments
Post a Comment